Confounding Variables in Quantitative Studies 定量研究中的混雜變數:如何識別與避免
開篇
在定量研究中,混雜變數會干擾研究結果,導致不準確的結論。為了確保研究的有效性,避免混雜變數是關鍵。透過隨機化研究條件並保持研究問題的聚焦,可以大大降低混雜變數對結果的影響。
什麼是混雜變數?
混雜變數是未被測量但可能無意間影響研究結果的變數。它會同時影響自變數(你改變的條件)和因變數(你測量的結果),從而引發意外的研究結果。
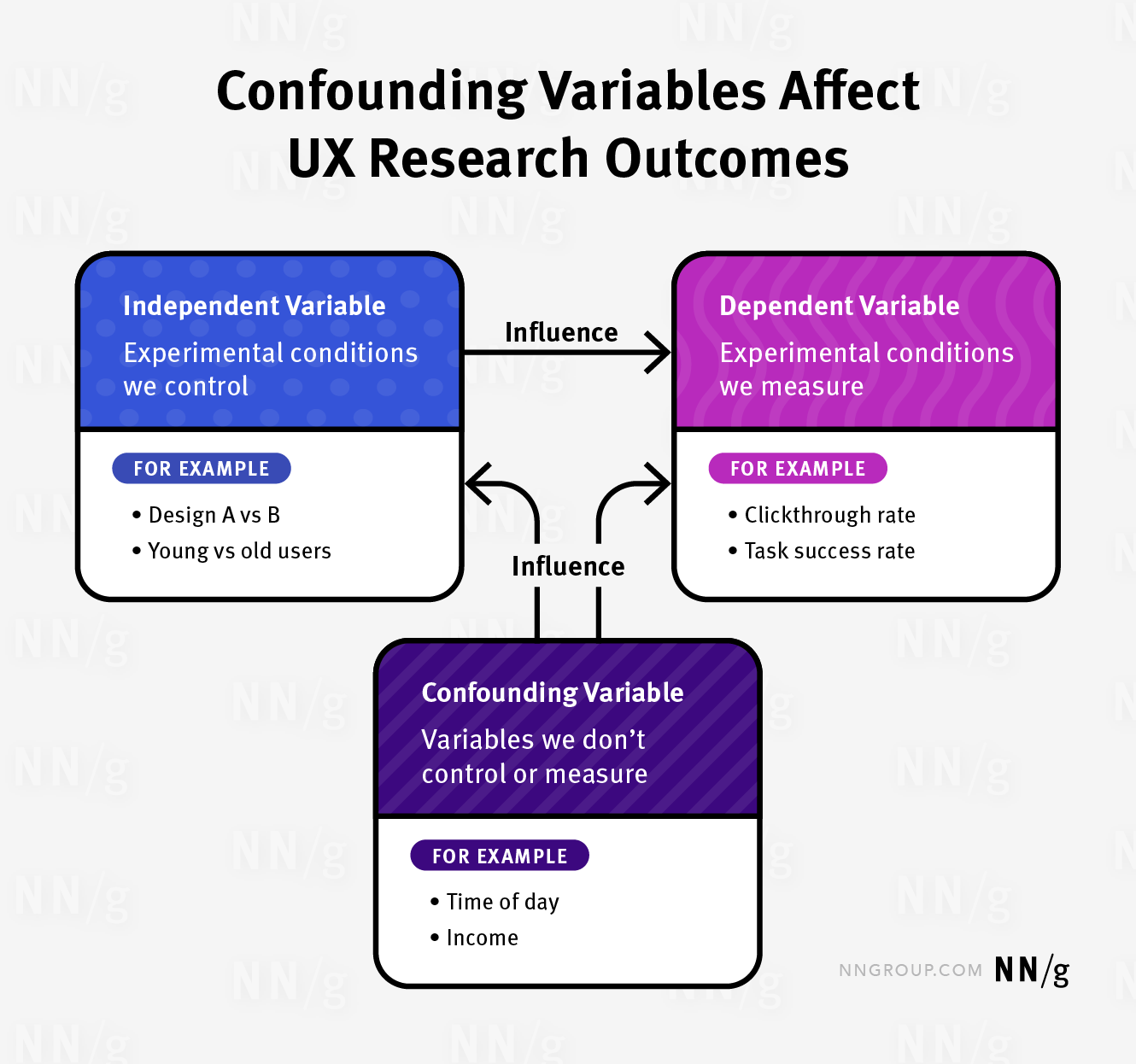
這張圖說明瞭混雜變數如何影響使用者體驗(UX)研究的結果。圖中顯示了自變數、因變數和混雜變數之間的關係:
- 自變數(Independent Variable):研究中可控的實驗條件,例如不同設計(設計A vs 設計B)或使用者年齡(年輕使用者 vs 年長使用者)。
- 因變數(Dependent Variable):研究中測量的結果,例如點選率(Clickthrough Rate)和任務成功率(Task Success Rate)。
- 混雜變數(Confounding Variable):未被控制或測量的變數,這些變數會影響研究結果。例子包括時間(Time of Day)和收入(Income)。
混雜變數同時影響自變數和因變數,可能導致研究結果不準確或難以解釋。因此,混雜變數會干擾研究的準確性,使得研究結果的可信度受到威脅。
這段內容說明瞭在一項研究中,混雜變數如何影響結果的可靠性,並提供了應對這些變數的方法。以下是具體解釋:
1 研究中的混雜變數:
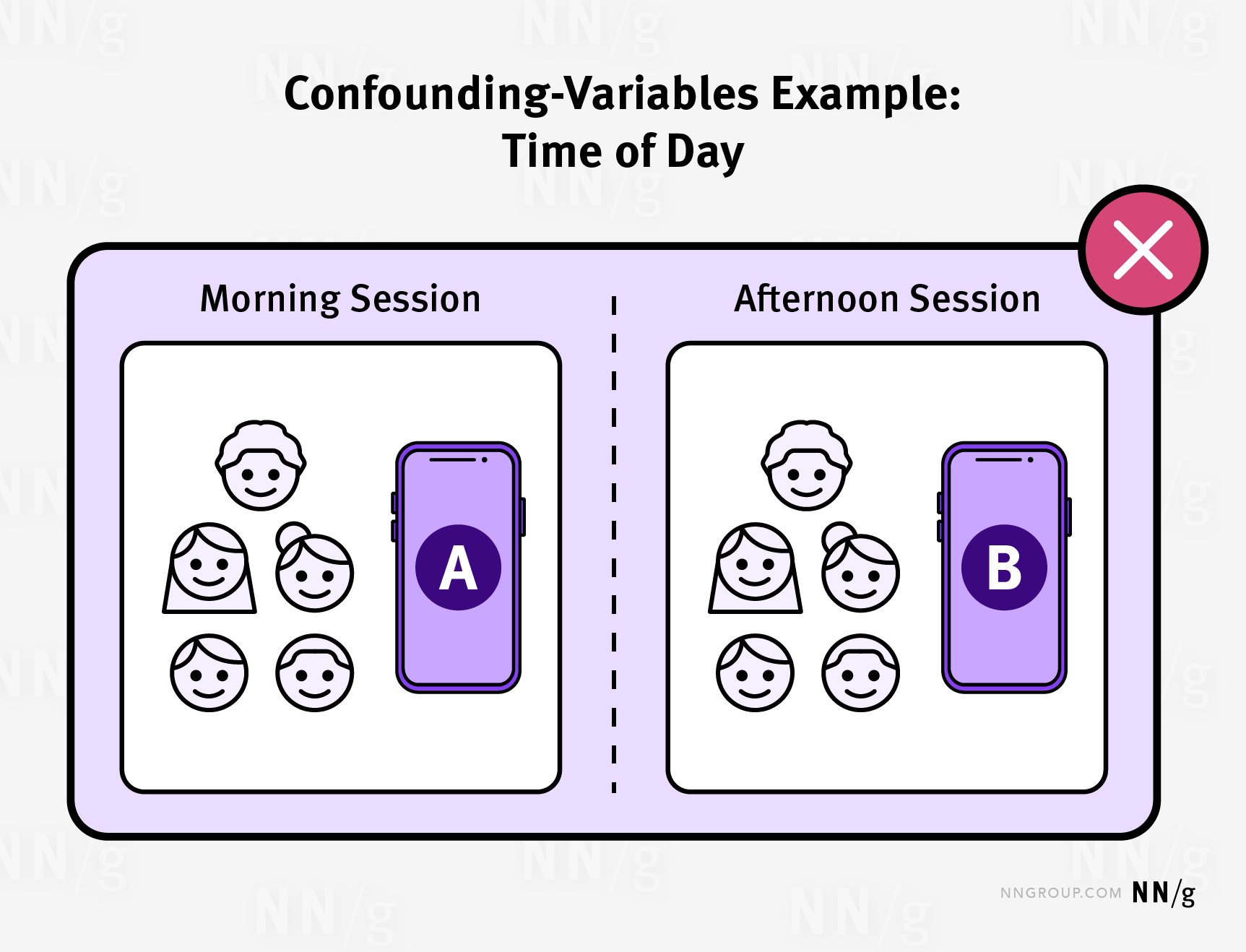
- 測試設計 B 的參與者之前已經有了使用該產品的經驗(來自早上的測試),這可能會影響他們對設計 B 的表現。
- 午餐可能讓參與者精力不足,從而影響下午的表現。
- 當天晚些時候,參與者可能會感到疲倦,導致任務表現下降。
這些混雜變數可能互相矛盾:參與者在下午可能因早上的經驗表現更好,但也可能因午餐後的疲倦表現更差。這使得研究結果的預測變得困難。
2 避免混雜變數的方法:
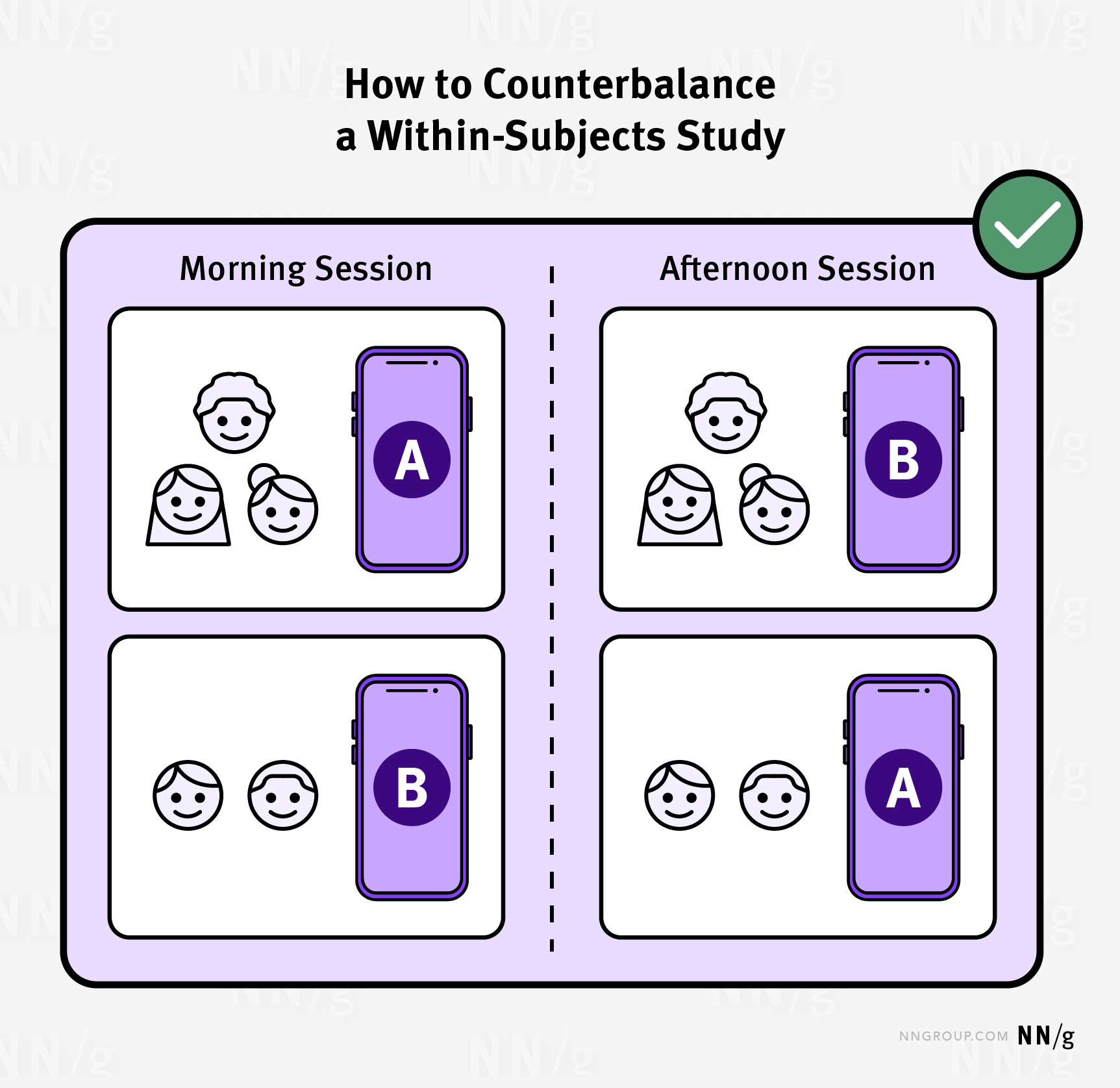
為了避免時間和學習效應,可以隨機將參與者分配到設計 A 或設計 B 的測試中。例如,一部分人在早上測試設計 A,另一部分人在下午測試設計 B。透過隨機化參與者接觸不同設計的順序,可以減少時間、精力耗盡、經驗或飢餓等因素的影響。
這種隨機化的方法有助於減少混雜變數對結果的影響,從而提高研究結果的可靠性和有效性。
混雜變數的更多例子:
| 變數 | 描述 | 解決方案 |
| 年齡影響 | 參與者的年齡會影響許多與使用者體驗相關的變數,包括滿意度、任務完成時間、任務成功率和閱讀能力。 | 為研究招募具有代表性的參與者年齡樣本。根據研究條件對參與者進行隨機分配,以便年齡在不同條件下均勻分佈。如果需要,記錄參與者的年齡以供後續分析。 |
| 季節性影響 | 根據當前季節的不同,參與者的行為可能有所不同。比較第四季度和第一季度的可用性研究可能會受到季節性變化的影響。 | 如果比較不同研究的結果,請考慮研究完成的時間。理想情況下,比較在相似時間段內收集的資料。 |
| 2019冠狀病毒病大流行 | 冠狀病毒大流行改變了人們與產品互動的方式,疫情前後收集的資料可能會受到其影響。 | 透過識別異常資料,排除大流行最嚴重時期的日期範圍。 |
| 市場競爭格局轉變 | 競爭對手的大型促銷或新品推出可能會影響使用者行為,使得評估設計更改的效果變得困難。 | 構建研究時避免重大市場動盪。 |
| 現有產品經驗 | 當比較兩種不同產品的任務完成時間等指標時,參與者之前對產品的體驗可能會使結果偏向一個方向。 | 招募具有不同經驗水平的參與者,或排除具有豐富產品經驗的參與者(如果適用)。 |
| 現有產品意見 | 使用者對正在測試的產品可能有預先存在的觀點,影響可用性或調查結果。在比較使用者對兩種產品的滿意度時,先前對產品的看法可能會導致結果產生偏差。 | 在招聘過程中,篩選極端積極或消極的產品情緒,並控制或排除這些參與者。 |
為什麼混雜變數重要?
混雜變數會影響研究的內部效度,即研究的可靠性和可重複性。如果研究結果受到混雜變數的幹擾,那麼基於這些錯誤結論做出的設計決策可能會浪費時間和資源。
避免混雜變數的最佳實踐:
- 使用被試內設計:如果可能,採用被試內設計並隨機化順序,減少誤差。
- 隨機分配組別:在被試間設計中,隨機分配條件組,確保每個參與者看到不同設計的順序是隨機的。
- 識別並控制混雜變數:在設計研究時,考慮所有可能的混雜變數,必要時在後續分析中控制它們的影響。
- 保持一致的測試環境:確保測試條件(如房間、裝置等)在整個實驗中保持一致。
- 考慮定性研究:如果難以控制混雜變數,考慮進行定性研究以避免偏差。
結論
在設計定量研究時,識別和控制混雜變數至關重要。透過仔細規劃和執行,你可以提高研究的內部效度,確保結果準確並能為決策提供有力支援。